Raise your hand if you’ve spent the last couple of years carefully crafting your AI prompts. Getting the wording just right. Adding “think step by step” or “you are an expert in…” to the beginning. Tweaking and testing until you got something halfway decent.
Yeah, me too.
And here’s the slightly humbling news I’ve been sitting with lately: prompt engineering, while still useful, is no longer the main event. The new skill that’s quietly taking over — especially in data and AI workflows — is something called context engineering. And once I understood what it actually meant, I couldn’t stop thinking about it.
Wait, Isn’t Prompt Engineering Still a Thing?
Yes! But it’s starting to feel a bit like writing the perfect instruction manual when the real problem is that the person doing the task doesn’t have access to half the tools they need.
Prompt engineering is about how you talk to an AI model. You craft the right words, set the right tone, give it examples. That’s useful — but it’s inherently limited to a single interaction. It’s tactical.
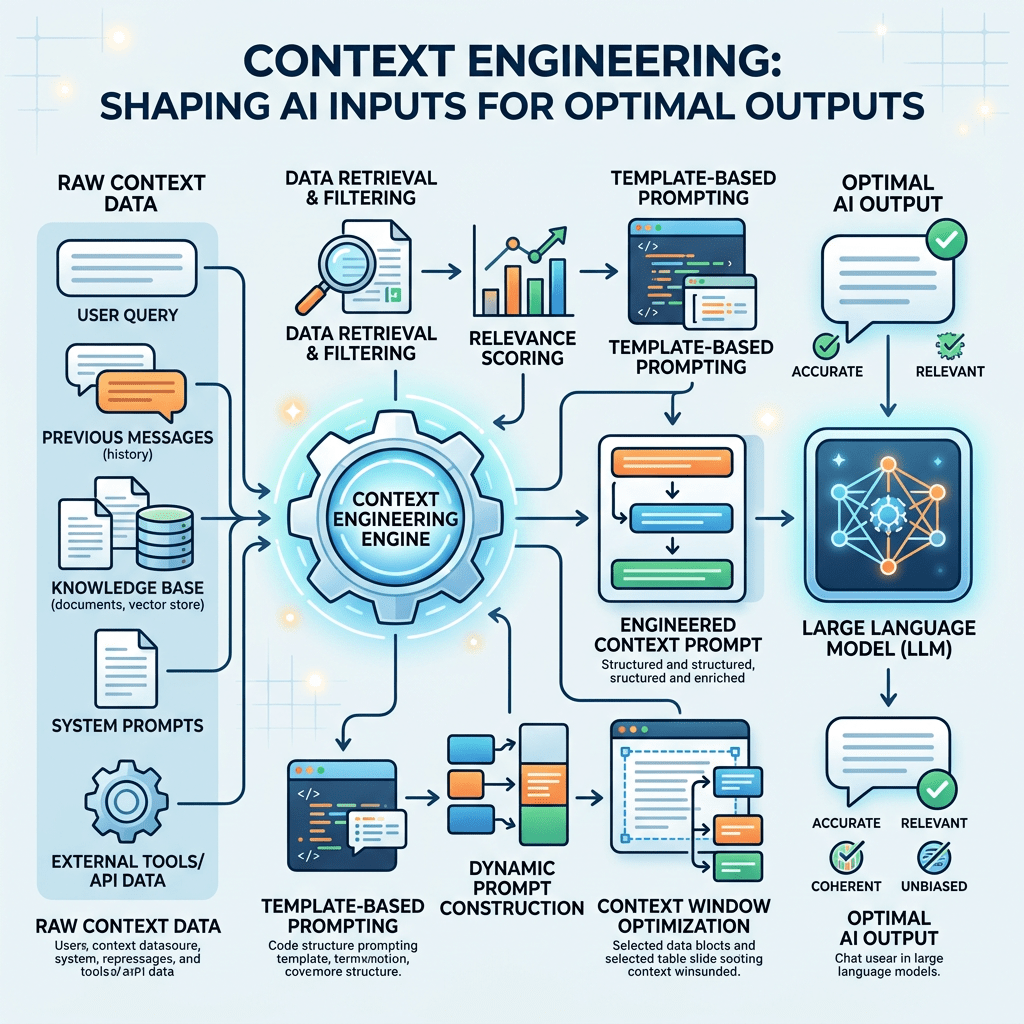
Context engineering is about what the AI knows when it’s working. It’s the practice of designing and managing all the information, memory, data, and tools that an AI system has access to — so that at the moment it needs to do something useful, it actually has the right stuff in front of it.
A Gartner piece I came across recently put it really cleanly: context engineering is “the practice of regulating and optimising the AI environment so that the model always sees the right data, with the right structure, under the right rules, at the right moment.” That phrase — right data, right structure, right moment — honestly kind of blew my mind, because it’s basically describing good data work. Which means data people are actually really well positioned for this shift.
So What Does Context Engineering Actually Include?
Here’s where it gets interesting. Context engineering isn’t just one thing — it’s more like an umbrella for a whole set of practices:
- RAG (Retrieval-Augmented Generation): Feeding the AI relevant documents or data at query time, rather than hoping its training data covers your specific use case.
- Memory management: Deciding what the AI “remembers” across conversations or agent steps — and what it forgets (token budgets are very real!).
- Tool orchestration: Giving AI agents access to the right functions, APIs, and data sources at the right time.
- Data structuring for retrieval: Chunking, embedding, and organizing your data so an AI can actually find and use it effectively.
- State persistence: Managing what an AI agent knows across multi-step workflows — especially important as agentic tasks get longer and more complex.
Notice how much of this sounds like… data engineering? Schema design? Data quality work? Yeah. That’s not a coincidence.
Why This Matters for Data Professionals Right Now
I’ve been watching this shift play out in real time. The bottleneck for AI performance is no longer the model itself — today’s models are genuinely impressive. The bottleneck is the data feeding the model. Is it clean? Is it well-structured? Is the right information retrievable at the right moment?
A 2026 State of Context Management Report found that 82% of IT and data leaders now agree that prompt engineering alone isn’t enough to power AI at scale. And companies are actively hiring people who can design these context pipelines — people who understand data quality, retrieval systems, and how to structure information for AI consumption.
If you’ve been worried that AI is going to hollow out data roles, this is a genuinely encouraging counter-signal. The skills that make someone a strong data professional — understanding data quality, schema design, pipelines, governance — are exactly the skills that context engineering demands. We’re not becoming obsolete. We’re becoming essential in a new way.
Where to Start Building This Skill
I’m still in the early stages of exploring this myself, but here’s what I’ve found helpful so far:
- Learn the basics of RAG. There are great tutorials on building simple retrieval pipelines with tools like LlamaIndex or LangChain. Even a small toy project helps you understand how chunking and embedding actually work in practice.
- Look at your existing data differently. When you look at a dataset, start asking: “If an AI agent needed to answer questions from this, what would make that easier?” Column naming, documentation, consistent formatting — it all matters more now.
- Experiment with agentic tools. Tools like Cursor, Claude, and various AI copilots give you a window into how context management plays out. Pay attention to what breaks and why — it’s almost always a context problem.
- Get familiar with vector databases. Pinecone, Weaviate, pgvector — these are becoming core infrastructure. Understanding what they do and when to reach for them is a solid concrete skill to add to your toolkit.
The thing I find most exciting about context engineering is that it doesn’t live in ML-land exclusively. It sits right at the intersection of data work and AI — and that’s exactly where I want to be spending my time and energy in 2026.
I’m planning a proper hands-on tutorial soon where I’ll build a small RAG system from scratch and walk through all the decisions along the way, so stay tuned for that.
In the meantime — have you started hearing about context engineering in your own work? Is your team already thinking about this, or is it a new concept for you? Drop a comment below — I’d genuinely love to know where everyone’s at with this one.

Leave a comment